

Key Takeaways
Traditional analytics tools like Google Analytics and Mixpanel break in DeFi because they cannot see wallet activity and onchain-data.
Session-level data and onchain transaction data live in separate systems with no shared identity, making attribution, funnel analysis, and retention measurement impossible without a purpose-built layer.
The three approaches to DeFi analytics: SaaS platforms that handle data ingestion and provide out-of-the-box dashboards (fastest time-to-value, least engineering overhead); custom data pipelines built on blockchain indexers (highest flexibility, highest engineering cost); and hybrid stacks combining both (the most common architecture at scale).
Most teams underestimate the ongoing cost of custom analytics pipelines. New chain support, API changes, and schema migrations each require dedicated engineering time that scales with protocol complexity rather than team size.
Using an existing analytics platform lets teams spend less time building data infrastructure & analytics, and more time shipping products users want.
A practitioner's guide to understanding what actually works for measuring growth, users, and attribution in crypto and DeFi (decentralized finance.)
In 2020, Uniswap caught significant backlash for enabling Google Analytics on its interface. Interfaces later added Hotjar for session recording, which the community treated as an outright privacy violation. The criticism was understandable: users interacting with permissionless, non-custodial protocols expected their activity to stay private.
But behind the backlash is a real problem that hasn't gone away. DeFi teams sought to understand how people find and use their apps & protocols, and the analytics tools built for Web2 don't fit cleanly into a world where the most important user actions happen not just offchain but onchain.
Privacy is top of mind for crypto builders and users. But building without data means you're flying blind. Builders are trapped in a contradiction.
To build user-facing products, you need to measure growth, understand user behavior, and prove ROI on campaigns, but the standard tools for doing this come loaded with invasive tracking, third-party cookies, and data collection practices that violate the ethos of the space.
Six years later, the tooling landscape has matured considerably. There are now niche tools, open data platforms, and multiple valid approaches to solving the analytics problem in DeFi. But the landscape is also fragmented, confusing, and full of tradeoffs that aren't obvious until you've committed significant engineering time.
This guide covers the major platforms, the do-it-yourself approaches, and the quirks you'll discover only after you start using them. It's written for founders and growth leads at crypto neobanks, prediction markets, and DeFi apps who need to make a decision.
Formo came out of this frustration about the state of analytics tooling in DeFi. Building privacy-friendly, crypto-native analytics for the DeFi space means having to be creative based on constraints.
We've reviewed nearly all major analytics tools in the space to come up with a solution that balances usefulness, privacy, and security. Book a demo.
The Core Problem: Two Data Silos That Don't Talk to Each Other
Before comparing tools, it helps to understand why DeFi analytics is fundamentally harder than traditional web and product analytics.
In a traditional web or mobile app, the entire user journey happens mostly inside your application. A user visits your site, creates an account, clicks around, and maybe pays you. Tools like Google Analytics, Mixpanel, or Amplitude can see all of this because the user's browser is the source of truth.
In crypto and DeFi, the user journey is split across two completely different data planes. The offchain part is familiar: someone sees a tweet, clicks a link, lands on your interface, connects a wallet. The onchain part is where the money moves: swaps, deposits, and transfers. These two halves live in different databases, use different identifiers (cookies vs. wallet addresses), and follow different data models. In addition, some power users and agents live entirely onchain.
The result is a gap that no single tool solves perfectly. Every platform and approach in this guide represents a different bet on how to bridge that gap, and each one makes different tradeoffs in the process.
DeFi Analytics Taxonomy
Broadly, DeFi teams use one of four approaches, often layering multiple together.
Traditional web / product analytics like Google Analytics, Mixpanel, Amplitude, Segment, or PostHog. These handle offchain behavior well but are blind to onchain activity without significant custom instrumentation. Often requires custom-build pipelines to connect with onchain data.
Crypto-native analytics like Formo, Spindl, Cookie3. Built specifically for the offchain-to-onchain user journey, with unique features designed for DeFi and crypto teams. Handles identity stiching, linking wallets, and wallet labeling.
Onchain data platforms like Dune or DefiLlama. You can use them to query blockchain data directly to build dashboards, but they don't track offchain behavior (who viewed what, where they came from). Half of the user's journey is missing.
Custom-built pipelines using subgraph indexing (via Goldsky, Ponder, or similar infrastructure), direct RPC indexing, or data warehouse stacks stitched together by your engineering team. Building and maintaining custom dashboards often distracts the engineering team from shipping product.
Most serious DeFi teams end up using tools from at least two approaches.
Traditional Web and Product Analytics Tools
Google Analytics (GA4)
The default choice for most teams that haven't thought deeply about analytics yet. GA4 is free, low-friction, and handles basic traffic and campaign attribution. It can tell you where visitors come from, which pages they view, and roughly how your marketing channels perform.
What it actually does well: Campaign UTM tracking. Traffic source analysis. Bounce rate and session data. Integration with Google Ads if you're running paid campaigns (and yes, some DeFi projects do).
Where it falls apart: GA4 has no concept of a wallet. When a user connects their wallet and executes a swap, GA4 sees a button click at best. It cannot attribute that onchain action back to the marketing campaign that brought the user in. You also inherit Google's data collection model, which sits uncomfortably with the privacy expectations of crypto users. GA4 uses cookie-based tracking, requires consent banners in GDPR jurisdictions, stores IP addresses, uses device fingerprinting, and feeds data into Google's broader advertising ecosystem.
Mixpanel
A well-known product analytics tool with event-based tracking, funnels, retention analysis, and cohort breakdowns. More useful than GA4 for understanding product behavior, but still designed around web2 users and tarditional web applications.
What it does well: Funnel analysis ("what percentage of users who connect a wallet complete a swap?"). Retention curves. Custom event tracking with properties. The query builder is genuinely good for non-technical team members.
Where it falls apart: Mixpanel identifies users via its own ID system. Mapping that to wallet addresses requires custom instrumentation. You'll need to fire events server-side when onchain transactions confirm, match them to Mixpanel user profiles, and maintain that mapping yourself. This is doable but fragile, and it means you're maintaining a pseudo-identity layer that duplicates what a crypto-native tool would handle natively.
Amplitude
Similar to Mixpanel in capabilities.
What it does well: Strong behavioral analytics, good visualization tools, and a mature experimentation platform (A/B testing, feature flags). Amplitude tends to be preferred by larger organizations because of its governance and data management features.
Where it falls apart: Same fundamental gap as Mixpanel. No native onchain awareness. You're bolting blockchain data onto a system designed for app events. Amplitude's free tier is limited to 50,000 monthly tracked users (MTUs), which gets expensive once you scale.
Segment
A customer data platform (CDP) less focused on being an analytics tool.
What it does well: Twilio Segment collects events from your application and routes them to any number of downstream tools (Mixpanel, Amplitude, data warehouses, CRMs). In theory, you could use Segment as the collection layer and pipe events to multiple analytics platforms.
Where it falls apart in DeFi: Twilio Segment has no native blockchain support. You'd still need to build the onchain event ingestion yourself, push those events into Segment, and maintain the wallet-to-user identity mapping. You end up building a significant amount of custom infrastructure to make Segment work as a unifying layer, and you're still dependent on downstream tools that don't understand wallets natively.
PostHog
PostHog offers product analytics, session replay, feature flags, and A/B testing in a single platform. The session replay feature is genuinely useful for DeFi interfaces because you can watch exactly where users get confused during complex flows (multi-step approvals, bridge interactions, etc.).
What it does well: PostHog's open-source nature means you can inspect exactly what data is being collected, which is a meaningful advantage when your users care about privacy. Self-hosting is also an option but introduces operational overhead that most early-stage DeFi teams shouldn't take on.
Where it falls apart: Same story. PostHog tracks what happens in the browser, not what happens onchain. Its data warehouse feature (HogQL) is powerful, but connecting it to onchain data still requires custom engineering.
Summary of Traditional Analytics Tools in DeFi
Traditional analytics tools are not without merit in DeFi. They solve the offchain half of the problem well. But they all share the same fundamental limitation: the moment a user's journey moves onchain, these tools lose visibility. Bridging that gap requires custom engineering work, and at that point you're building and maintaining your own analytics infrastructure on top of someone else's platform that was never designed for your use case.
For teams that try to stitch together a full picture using Web2 tools alone, the typical result is a Frankenstein stack: GA4 for traffic, Mixpanel for product events, Segment to pipe data around, a custom ETL to pull onchain data, and a data warehouse to try to join it all together.
Each piece solves one slice of the problem, but the integration burden is substantial (demanding a dedicated data team), the identity resolution across systems is fragile, and the maintenance cost is ongoing. Most DeFi teams that go down this path end up with dashboards that are perpetually 80% accurate and one schema change away from breaking.
Crypto-Native Analytics Platforms
These tools were built specifically for the DeFi / crypto apps. They attempt to bridge the offchain-onchain gap natively.
Using an crypto-native analytics platform lets teams spend less time building data infrastructure & analytics, and more time shipping products users want.
Formo
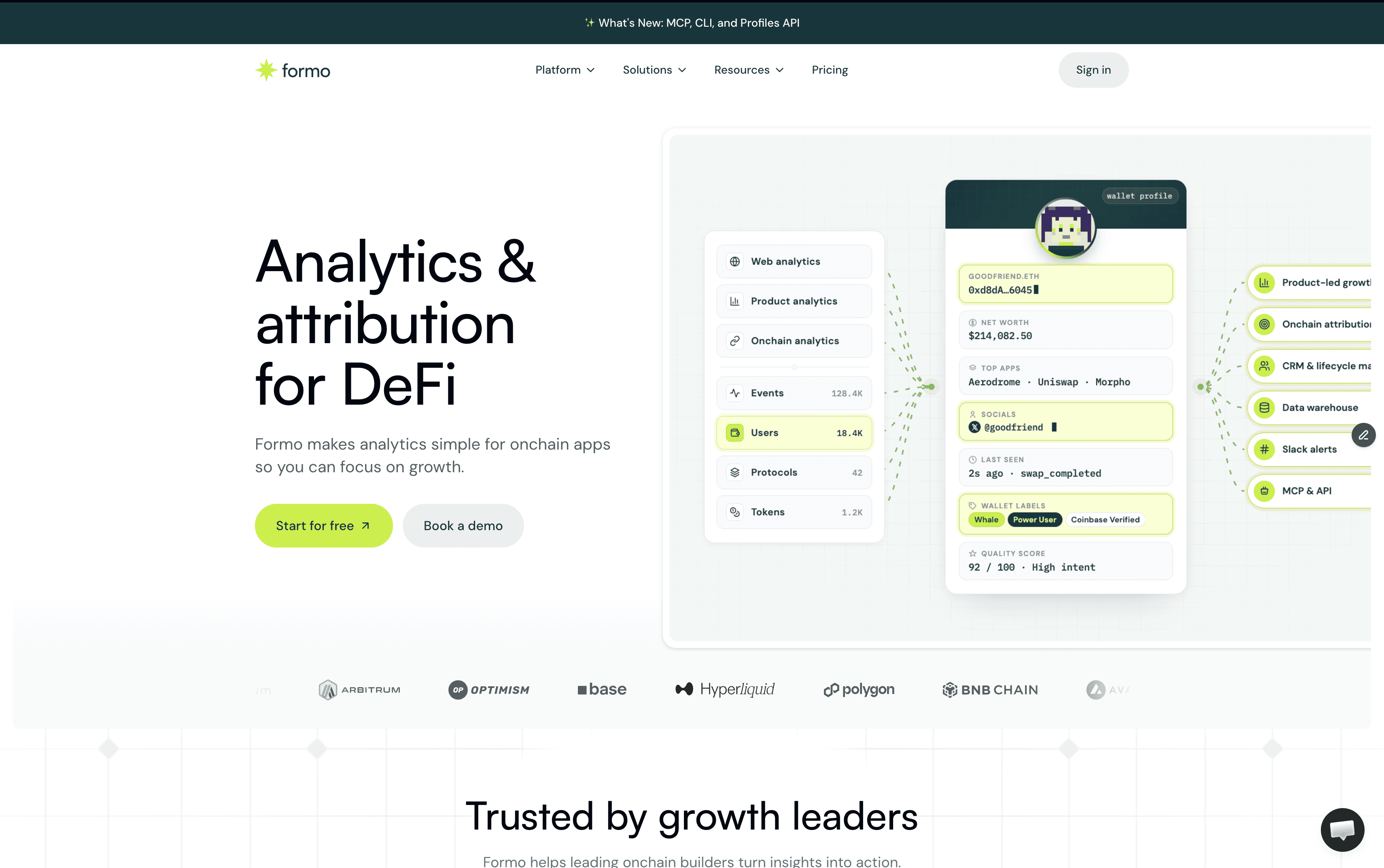
A DeFi-native analytics platform that combines web, product, and onchain analytics into a single platform. Formo connects offchain user behavior (page views, campaigns, UTM tracking) to onchain actions (swaps, deposits) by stitching together the whole user journey. Supports wallet intelligence across 40+ EVM chains with automatic wallet detection.
What it does well:
Wallet-level user profiles that unify offchain browsing behavior with onchain transaction history. Onchain attribution using three models (first-touch, last-touch, and linear) that connect specific marketing campaigns to actual onchain conversions.
Product analytics features comparable to Mixpanel or Amplitude (funnels, retention, cohorts) but with wallet addresses as the identity layer instead of email or user ID.
Multi-chain support without manual configuration per chain. Setup is lightweight, privacy-friendly, and secure through an open-source SDK.
Formo also natively ingests ERC-8021 builder code attribution data (more on this below), providing standardized onchain attribution alongside offchain tracking.
Comes with custom dashboards and an AI analyst for data exploration.
Identity stitching: Formo uses wallet addresses as the primary identity, which provides a meaningful advantage over traditional analytics. When a user connects their wallet, Formo links that wallet to the offchain session data it has already collected (referrer, UTM parameters, page views, etc). Cross-session and cross-wallet identity resolution happens automatically without invasive tracking or device fingerprinting.
Where it falls short: No session replay. No feature flags or A/B testing. If you need to watch users interact with your interface or run experiments on UI variants, you'll need a separate tool.
Best for: DeFi teams that need the full picture from first visit to onchain action, especially those running growth campaigns and needing to measure actual ROI in terms of onchain conversions.
Spindl
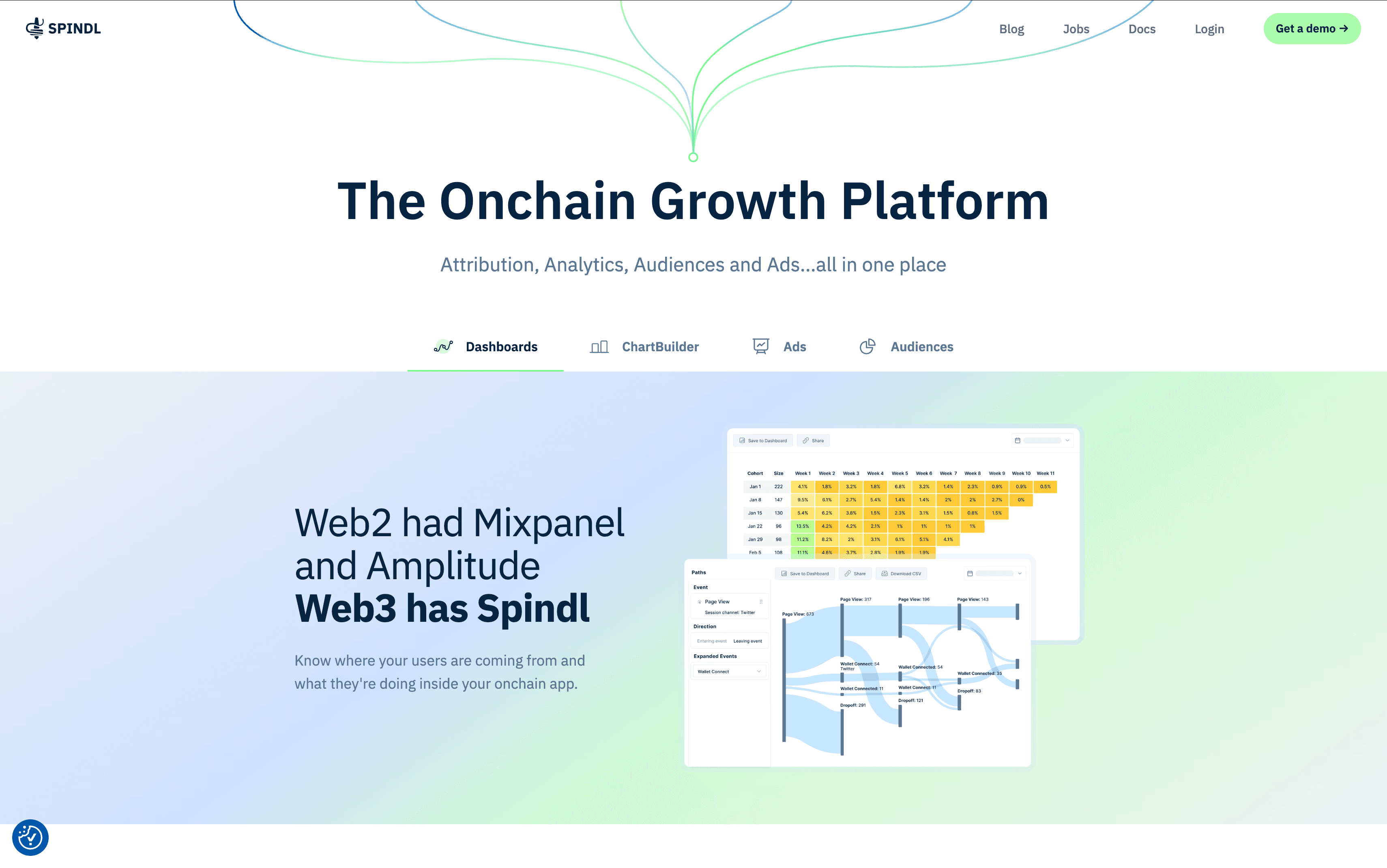
An attribution and ads platform acquired by Coinbase in early 2025 and integrated into the Base ecosystem. Spindl's primary focus is connecting offchain ad impressions to onchain wallet actions, essentially solving the "did this ad actually lead to a deposit?" problem.
What it does well:
Attribution modeling that maps advertising spend to onchain outcomes.
Wallet-level CAC (customer acquisition cost) and LTV calculations.
Integration with traditional ad platforms (including a partnership with AppsFlyer for gaming).
Dashboard builder comparable to Looker or Tableau.
Where it falls short: The Coinbase acquisition means Spindl's roadmap is now tied to Coinbase's priorities, and Base integration is front and center. If you're building on chains outside the Coinbase ecosystem, the level of support may vary.
The quirk: Spindl's strength is specifically in paid acquisition attribution. If you're not running ads or paid campaigns, much of what Spindl offers isn't relevant. Teams doing purely organic growth (content, community, protocol incentives) may find less value here.
Best for: Teams with paid acquisition budgets who need to prove ROI on ad spend in terms of onchain actions. Especially relevant for gaming and consumer-facing DeFi apps.
Cookie3
A Web3 analytics platform with a "MarketingFi" angle, combining offchain and onchain analytics with a CRM and campaign management tools. Cookie3 has over 170 dapp integrations and a KOL (Key Opinion Leader) intelligence feature for influencer marketing.
What it does well:
Unified analytics that connects website behavior to onchain activity.
KOL tracking and attribution (useful where influencer marketing is a major channel).
Campaign manager for building and tracking marketing funnels.
Where it falls short: The platform's token-economic layer may be a distraction for teams that just want straightforward analytics. Limited wallet intelligence and dashboarding capabilities.
The quirk: Cookie3's KOL Intelligence feature is unique. In crypto, where a single tweet from the right person can drive more deposits than a month of paid ads, being able to measure and attribute KOL impact is valuable. But it also means the platform is optimized more for marketing teams than product teams.
Best for: Marketing-heavy crypto projects, especially those investing in influencer campaigns and needing to attribute KOL impact to onchain outcomes.
Addressable
An ads platform focused on connecting wallet addresses to advertising audiences. Addressable's core proposition is targeting: identifying wallet holders across advertising channels and measuring the conversion from ad impression to onchain action.
What it does well:
Wallet-to-ad audience matching (finding your onchain users in advertising platforms).
Built-in wallet targeting features through ads.
Focuses on the acquisition side of the funnel.
Where it falls short: Less focused on product analytics and retention. If you need funnel analysis, cohort behavior, or product usage patterns, Addressable doesn't cover that territory as deeply. More of an advertising tool than a full analytics platform. If you don't already know your ICP, targeting may be tricky.
Best for: Teams with significant paid advertising budgets looking to target specific, known wallet segments across ad platforms.
Onchain Data Platforms
These platforms let you query blockchain data directly. They're powerful for ecosystem-level analysis but may not track metrics and behavior for specific apps and protocols well. Only for onchain data, limited to no support for web and product analytics.
Dune
Dune transforms raw blockchain data from 100+ networks into SQL-queryable tables. Anyone can write queries, build dashboards, and share them publicly.
What it does well: Flexibility. If you can write SQL, you can answer almost any onchain question. Dune's community has built tens of thousands of public dashboards, and you can fork and modify any of them. The data is comprehensive, covering raw transactions, decoded smart contract events, token transfers, and more. Support for 100+ chains as of 2025.
Where it falls apart: Dune tells you what happened onchain, not why. You can see that 500 wallets deposited into your protocol last Tuesday, but you can't tell whether they came from a Twitter campaign, a Discord announcement, or a competing protocol's incentive program ending. There is no offchain tracking whatsoever.
The quirk: Qery performance on the free tier can be slow during peak hours. Also, because Dune dashboards are public by default (private queries require a paid plan).
Best for: Protocol analytics, community-facing dashboards, competitive research, and any analysis that's purely onchain.
DefiLlama
DefiLlama tracks TVL, DEX volumes, lending data, yields, and more across 500+ blockchains and 6,700+ protocols. It's completely free, open-source, has no token, runs no ads, and accepts no payments from listed projects.
What it does well: Reliable, unbiased protocol metrics. Because DefiLlama has no token and no paid listings, its data is widely trusted by investors, researchers, and media. The API is free and well-documented. New protocol integrations are community-contributed via GitHub.
Where it falls apart: DefiLlama is not a product analytics tool. It tells you aggregate protocol health (how much TVL you have, how it compares to competitors) but nothing about individual user behavior, marketing attribution, or product usage patterns.
The quirk: DefiLlama added risk scores for protocols based on audit history and liquidity volatility. This makes it useful not just for your own analytics but for due diligence when integrating with other protocols. Also, because all data comes directly from smart contracts (not from project-reported numbers), it's hard to game.
Best for: Protocol benchmarking, competitive TVL tracking, investor reporting, and getting a macro view of DeFi market dynamics.
The Build-Your-Own Approach
For teams with engineering resources and specific requirements, building a custom analytics pipeline is a legitimate option. But it's important to understand what "build your own" actually entails, because the scope is larger than most teams initially estimate.
The analytics problem in DeFi spans two distinct data planes, and a custom build needs to cover both.
The onchain half involves indexing blockchain data: your smart contract events, transaction receipts, token transfers, and wallet interactions. This is the part most teams think of first.
The offchain half is everything that happens before and around the onchain action: web traffic, page views, referrer sources, UTM parameters, session data, wallet connection events, and product interactions within your interface. This is the part that often gets underestimated or forgotten entirely.
A custom pipeline that only covers onchain data is only half an analytics solution. You'll know what happened on the blockchain, but not why. You won't know which marketing campaign drove those deposits, what the conversion rate is from landing page to first transaction, or where users drop off in your onboarding flow.
Subgraphs (Goldsky, Envio, and others)
Subgraphs let you define which smart contract events to index and then query them via GraphQL. You write a subgraph manifest specifying which contracts, events, and entities to track, deploy it, and then query the indexed data. Infrastructure providers like Goldsky and Ponder have made this significantly easier by handling the hosting, scaling, and reliability of subgraph indexing.
When it works well:
Protocol-specific analytics where you need real-time access to your own smart contract events.
If you need to know "how many unique wallets deposited into Pool X in the last hour" and your frontend needs that data for display, a subgraph is often the right tool.
The data model is defined by you, so you have full control on how you structure your data. (Comes with the responsibility.)
When it breaks down: Subgraphs index your smart contracts, but not everything you care about is onchain. Subgraphs don't track offchain behavior, can't tell you where users came from, and don't help with marketing attribution. If you need to analyze user behavior across multiple protocols, correlate offchain marketing data with onchain actions, or build cohort-based retention analysis, a subgraph alone is insufficient. Also, subgraphs are deterministic and process blocks sequentially, which means they can't easily handle cross-chain data or offchain events.
Direct RPC Indexing
The most bare-metal approach. You run your own nodes (or use providers like Alchemy, Infura, or QuickNode) and build an ETL pipeline that reads blocks, decodes transactions, filters for relevant events, transforms the data, and loads it into a database.
When it works well: Maximum flexibility on the onchain side. You control every aspect of the data pipeline and can optimize for your specific query patterns. Large DeFi protocols like Uniswap and Aave have teams that do exactly this.
When it breaks down: Operational complexity is high. You need to handle chain reorgs, RPC rate limits, data gaps from node downtime, schema migrations, data quality, reliability, and scaling as your protocol grows. Running dedicated data infrastructure can be expensive and demands data engineering expertise, which your team may not have in-house. And this still only covers onchain data. You need entirely separate infrastructure for web analytics, product analytics, and session tracking.
Technical quirk: One big gotcha is chain reorgs. When the chain reorganizes (blocks get replaced), your indexed data becomes invalid. Handling this correctly requires either re-indexing affected blocks or maintaining a "finality buffer" that only treats data as confirmed after a certain number of confirmations. Get this wrong and your dashboard will show phantom transactions that never actually happened.
Data APIs
Data APIs deliver metrics (transformed data) through an API. These pre-processed metrics can encompass a wide range of data, and providers continually expand their offerings with new and specialized metrics, each trying to carve out new niches.
Instead of indexing blockchain data yourself, you use Data APIs and build a custom frontend and data pipeline on top.
When it works well: Internal dashboards, automated reporting, and analytics that are primarily onchain-focused. Data APIs lets you execute queries programmatically and retrieve results, which you can then combine with offchain data in your own data warehouse.
When it breaks down: API rate limits, reliability, scalability and query execution times can be unpredictable. Building a production application on top of a third-party query API introduces dependencies you can't fully control. And again, these APIs give you onchain data only.
Internal Data Warehouse Aggregation (the "Frankenstein" approach)
Some teams attempt a "best of all worlds" approach by piping data from multiple sources (GA4 or PostHog for web traffic, a subgraph for onchain events, Dune for broader onchain data, their own backend for application events, Segment for event routing) into a central data warehouse (BigQuery, Snowflake, Clickhouse) and building analysis on top.
When it works well: Large teams with dedicated data engineers. This approach gives you maximum analytical power because you can join any data source against any other. Want to know the retention rate of users who came from Twitter, connected a wallet within 5 minutes, and deposited more than $10,000? With a unified warehouse, this is a single query.
When it breaks down: Complexity. You're maintaining multiple data ingestion pipelines, managing schema compatibility across sources, and building your own identity resolution layer (linking browser sessions to wallet addresses to onchain transactions). Each tool in the stack has its own data format, its own quirks, and its own failure modes. The identity resolution piece alone is a significant engineering challenge: matching a cookie-based browser session from GA4 to a wallet address from your application to a transaction hash from a subgraph requires custom logic that breaks whenever any upstream tool changes its data format.
The Unsolved Analytics Gaps in DeFi
It's worth being explicit about what a custom-build approach requires for the full DeFi analytics stack. Even if you already have a subgraph of indexer for your smart contract events, you still need several other components:
Web analytics: Page views, session tracking, referrer detection, UTM parameter capture. Most teams fall back to GA4 or PostHog for this, which means accepting their data collection practices or self-hosting PostHog.
Product analytics: Funnels, retention, cohort analysis, feature usage. These require event instrumentation throughout your application and a system to store and query that data.
Onchain analytics: DeFi portfolio data, token balances, wallet labels, wallet scoring, transaction frequency, and first / last onchain.
Identity resolution: The hardest piece. Linking an anonymous browser session to a wallet address to onchain transactions requires a custom identity layer. Cookie-based session IDs expire, users clear browsers, and wallet connections happen asynchronously. Building reliable identity stitching from scratch is a multi-month engineering project.
Attribution: Connecting marketing spend (UTM parameters, ad campaigns, referral links) to onchain outcomes. This requires joining offchain session data with onchain transaction data at the wallet level, with proper attribution windowing and multi-touch modeling.
The total scope of a truly custom analytics build that covers both offchain and onchain data is closer to building an entire data platform than most teams realize.
Comparison Table
Here's a look at what each category of tool actually provides. Checkmarks indicate native, out-of-the-box support. "Custom" means it's possible with engineering work but not built in.
Capability | Traditional Analytics (GA4, Mixpanel, etc.) | Crypto-Native SaaS (Formo) | Onchain Platforms (Dune) | Custom Build |
|---|---|---|---|---|
Web traffic analytics | Yes | Yes | No | Custom |
Product analytics (funnels, retention) | Yes | Yes | No | Custom |
Onchain event tracking | No | Yes | Custom | Custom |
Wallet-level user profiles | No | Yes | No | Custom |
Marketing attribution (offchain to onchain) | No | Yes | No | Custom |
Session replay | Some | No | No | Custom |
Multi-chain onchain data | No | Yes | Yes | Custom per chain |
SQL-based querying | No | Yes | Yes | Custom |
Wallet labeling / intelligence | No | Yes | Community-labeled | Custom |
Privacy-friendly (cookieless) | No (most) | Yes | N/A (public onchain data) | Depends on implementation |
Self-hostable | PostHog only | No | No | Yes |
ERC-8021 builder code support | No | Yes | No | Custom |
Privacy matters in DeFi. The analytics tools you choose should reflect that. Here's how the major approaches compare on privacy:
Privacy Feature | Formo | GA4 | Mixpanel / Amplitude / Posthog | Onchain Platforms (Dune, etc.) |
|---|---|---|---|---|
IP address storage | No | Yes | Yes | N/A (public data) |
Device fingerprinting | No | Yes | Varies | N/A |
Third-party cookies | No | Yes | No | N/A |
GDPR-compliant by default | Yes | No (requires consent banner) | No (requires consent) | N/A |
Open-source SDK | Yes | No | Yes | N/A |
Data fed to advertising networks | No | Yes (Google ecosystem) | No | N/A |
Identity model | Wallet address | Cookies (Third party) | Proprietary user ID | Wallet address |
The tradeoff is worth noting plainly: onchain data platforms like Dune don't raise privacy concerns because they only work with data that's already public on the blockchain.
Crypto-native tools like Formo bridge the offchain and onchain worlds while avoiding invasive tracking practices.
Web2 tools generally require consent mechanisms and collect more data than most crypto users are comfortable with because of invasive tracking such as device fingerprinting and IP collection.
Under-Discussed Problems in DeFi Analytics Nobody Talks About
The Data Fragmentation Problem
"Multi-chain data" understates the problem because the data fragmentation problem is broader than just chains. Data in DeFi is fragmented across three dimensions:
Chains: Each blockchain has different block times, event formats, RPC behaviors, and finality guarantees. A user who bridges assets from Ethereum to Arbitrum and then interacts with your protocol on Arbitrum needs to be tracked as a single journey, not two unrelated events. Onchain platforms like Dune handle cross-chain data at their layer, but crypto-native analytics tools have to index each chain separately and maintain wallet identity across them.
Data silos: Web analytics (page views, sessions), product analytics (events, funnels), onchain analytics (transactions, token transfers), portfolio data (token holdings, DeFi positions), and internal databases all live in different systems with different schemas. Gathering this data together into a coherent picture of a single user's journey is a substantial engineering lift, whether you're building it yourself or relying on a platform to do it for you.
Channels: Users discover your protocol through Twitter, Discord, Farcaster, Reddit, direct links, aggregators, and influencer content. Each channel has different tracking capabilities and different levels of attribution fidelity.
How well tools handle this fragmentation varies significantly, and the quality of cross-chain and cross-channel identity resolution is one of the most meaningful differentiators among crypto-native platforms.
The Identity Resolution Problem
In Web2, a user is an email address. In DeFi, a user is a wallet address, except they might have ten wallets, and one wallet might be shared by a multisig of five people.
The basic case (one person, one primary wallet) is handled well by crypto-native tools. Formo, for example, links a wallet address to all offchain session data (referrer, UTM, page views) at the moment of wallet connection, creating a unified user profile that persists across sessions and devices. This wallet-level identity resolution is automatic and doesn't require invasive tracking or device fingerprinting.
But the reality is messier. Power users with multiple wallets appear as separate users in any wallet-based system. Sybil bots uses hundreds or thousands of fake accounts. Multisig wallets appear as single users when they're actually committees. Smart contract wallets (like Safe) interact through proxy contracts that may or may not be attributed to the right entity. And in DeFi, a significant percentage of interactions happen through aggregators or direct contract calls where the user never touches your frontend at all, making any tracking invisible.
The Privacy Paradox
Blockchain data is public. Anyone can see every transaction every wallet has ever made. And yet, connecting a wallet address to a person (or even to a browsing session) is considered invasive. This creates an odd situation: the onchain data is open, but the offchain-to-onchain link is sensitive.
Crypto-native tools handle this by using the wallet address as a pseudonymous identity rather than trying to resolve it to a real person. For example, Formo's approach is: no IP address storage, no device fingerprinting, no third-party cookies, and an open-source SDK that can be inspected. The identity layer is the wallet address itself, which is based on public onchain data.
But even pseudonymous tracking makes some users uncomfortable, especially when combined with rich offchain session data. The tension between "we need data to build better products" and "users expect privacy" is real and ongoing.
The Attribution Headache
Even with tools that bridge offchain and onchain data, attribution in DeFi is harder than in Web2 for structural reasons.
In DeFi, a user might discover your protocol through a tweet, research it on DefiLlama, ask about it in a Discord, and then interact with your smart contracts directly through Etherscan rather than your interface. That user never touched your frontend, and no analytics tool will capture that journey.
An attribution system captures UTM parameters, referrer data, and referral links during offchain sessions, then matches them to wallet connections and subsequent onchain transactions.
Attribution in web3 is complex. As you’ve seen in the above example, not everything you care about is onchain.Consider the following example user journey for a DEX called FooSwap with many touchpoints:
A user sees an tweet thread about an app on X (“referrer”) clicks on a referral link
The user visits the app’s website (fooswap.com)
The user visits the app (app.fooswap.com)
The user connects their wallet on the app
The user signs a token approval message
The user starts a swap transaction but the wallet has insufficient gas
The user abandons their transaction (“dropoff”)
The user revisits the app from another channel on Farcaster (“referrer”)
The user completes a swap transaction (“conversion”) emitting an onchain event
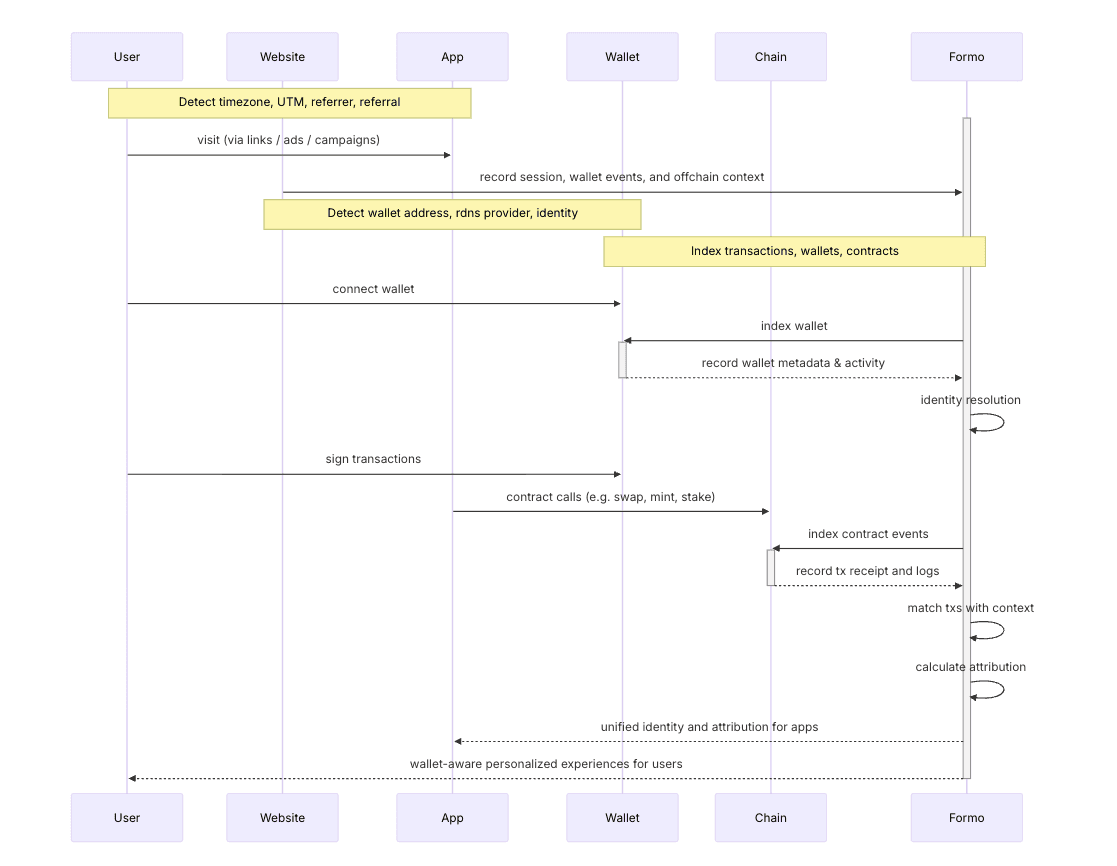
To understand the full user journey, we must navigate two different worlds: offchain and onchain. It’s imperative to trace the event sequence from initial engagement offchain to conversion onchain.
Formo solves attribution through three attribution models: first-touch (crediting the first marketing touchpoint), last-touch (crediting the most recent), and linear (distributing credit equally across all touchpoints). These models use a configurable lookback window to determine which offchain interactions should receive credit for an onchain conversion.
Using ERC-8021 Builder Codes for Onchain Attribution
A welcome development in the attribution space is ERC-8021, a standardized attribution protocol for EVM-compatible blockchains. Builder codes allow applications to claim credit for transactions they facilitate by appending standardized attribution data to transaction calldata.
The standard appends attribution data beyond the expected function arguments in the calldata. A parser reads from the end of the calldata, checks for the ERC marker (0x8021...8021) in the final 16 bytes, and extracts attribution information via a schema ID byte. The gas overhead is negligible (approximately 100-400 gas per transaction), and it requires no smart contract modifications or redeployments because it works with any EVM-compatible contract.
Builder codes provides onchain attribution that doesn't depend on offchain tracking at all. Multiple applications can receive attribution in a single transaction through comma-delimited codes, enabling multi-party revenue sharing models. Formo ingests ERC-8021 attribution data automatically through its offchain tracking SDK and smart contract events indexing pipeline, creating full-funnel analytics that connect marketing campaigns to real onchain metrics.
For protocols where a significant percentage of interactions happen through aggregators, direct contract calls, or other interfaces, ERC-8021 builder codes provide an attribution mechanism that works even when the user never visits your frontend.
Build vs. Buy: A Decision Framework
The "build vs. buy" question in DeFi analytics isn't binary. Most teams end up with a hybrid approach. Here's a framework for thinking about it.
When to Buy
Marketing attribution (connecting growth campaigns to onchain conversions). Building this yourself requires instrumenting your frontend, capturing session data, indexing multiple chains, building an identity resolution layer that links browser sessions to wallet addresses to transactions, and maintaining all of these pipelines. It's months of focused engineering work to replicate what a dedicated tool provides out of the box, and the resulting system needs ongoing maintenance as scale increases and edge cases surface. If you're spending money on growth and need to measure ROI, buying is almost always the right call.
Product analytics (funnels, retention, cohorts). Building your own funnel analysis, retention curves, and cohort breakdowns from scratch means building an event ingestion system, a storage layer, a query engine, and a visualization layer. This is essentially building an analytics product from zero. Unless analytics is your core product, the opportunity cost of your engineering team's time is hard to justify.
Identity resolution. Reliably linking anonymous browser sessions to wallet addresses to onchain transactions is one of the hardest technical problems in DeFi analytics. It requires handling cookie expiration, cross-device sessions, wallet provider differences, smart contract wallet interactions, and chain-specific finality rules. Getting this wrong means your attribution data is unreliable, which means every downstream analysis built on top of it is suspect. This is the single strongest argument for buying rather than building.
Wallet intelligence. Ingesting data from all major chains is a massive undertaking. Data pipelines, data engineering, reliability, scalability, RPCs, and data storage are nontrivial problems that you need to solve. Yes, onchain data is public. But without context and expertise the data lone is hard to make use of.
When to Build
Real-time onchain data for your application (not just analytics). If your frontend displays live protocol data (TVL, user positions, transaction history), subgraph indexing via Goldsky, Ponder, or similar infrastructure is the standard approach. This is infrastructure that serves your product, not just your analytics.
Highly specific analytical requirements. If you have needs that no off-the-shelf tool covers, you have the engineering team to maintain a custom pipeline, and the analytics are core to your product or business model (e.g., calculating complex incentive distributions based on multi-chain user behavior), a custom build may be justified.
Onchain-only analysis and research. Dune is excellent for ad hoc onchain research, competitive intelligence, and community-facing dashboards. They solve a different problem than product analytics or attribution, and they're the right tool for that job.
The Hidden Costs of Building
Teams consistently underestimate three things about custom analytics builds:
Maintenance cost. The initial build is the easy part. Ongoing maintenance includes handling chain upgrades, RPC provider changes, schema migrations, pipeline failures at 2am, and keeping up with new chains and standards. Budget at least one engineer's ongoing time for a production-grade pipeline, and more for multi-chain setups.
Time to value. A custom analytics pipeline typically takes 3-6 months to produce reliable data, during which time your team is making growth decisions without good information. Every month without proper attribution is a month of potentially wasted marketing spend.
Data quality. Custom pipelines are only as good as the edge cases you've anticipated. Chain reorgs, RPC timeouts, failed transaction handling, smart contract wallet interactions, bridging events, and multi-hop aggregator transactions all need to be handled correctly. Each one that's missed introduces inaccuracy that compounds over time.
The most expensive analytics setup is the one that doesn't answer the questions you need answered.
What a Practical Analytics Stack Looks Like for DeFi
For a DeFi team, here's what a realistic analytics setup looks like.
Early stage (pre-product-market-fit, <5 people): Formo for unified web, product, and onchain analytics with attribution out of the box. DefiLlama for protocol benchmarking and market context. Dune for ad hoc onchain analysis when you need to answer questions outside your own protocol. This gives you a complete picture without any custom engineering work.
Growth stage (active users, running campaigns, 5-20 people): Formo as the core analytics and attribution platform, covering the full funnel from traffic source through onchain conversion. Dune for deeper onchain research and internal dashboards.
Scale stage (significant TVL, multiple chains, 20+ people): Formo for attribution and product analytics across all chains. Dune for protocol-level research and community-facing dashboards. At this scale, you may also want a data warehouse to combine Formo's analytics data with your internal application data for custom analyses, or you can write more data into Formo and use it as your warehouse. Formo supports custom labels and properties.
The key principle across all stages: start with tools that natively understand both the offchain and onchain parts of the user journey. Trying to stitch together separate tools for web analytics, product analytics, and onchain data creates an engineering and maintenance burden that compounds over time. Spend less time on analytics, and more time shipping.
Final Thoughts
The DeFi analytics landscape in 2026 is dramatically better than it was even two years ago. The days of choosing between Google Analytics (which ignores the blockchain entirely) and building everything from scratch are over. There are now real, purpose-built tools for the crypto-specific problems of wallet identity, onchain attribution, and cross-chain tracking.
But no single tool covers everything, and the landscape is still maturing. The crypto-native platforms are young compared to their Web2 counterparts, with smaller teams and less battle-tested infrastructure. The onchain data platforms are powerful but solve a different problem than product analytics. And the build-your-own approach, while offering maximum flexibility, carries costs that most teams underestimate.
The best approach is to be clear about what questions you actually need answered, pick the simplest stack that answers them, and resist the urge to build custom infrastructure until you've outgrown the off-the-shelf options. The most important analytics insight for a DeFi protocol isn't which tool you use. It's whether you're asking the right questions about your users in the first place.
Disclosure: This review was authored by the Formo team. We've done our best to represent each platform fairly and accurately based on publicly available information as of March 2026. If you spot inaccuracies, we welcome corrections.
Looking for analytics for your onchain app? Book a demo.
FAQs
What makes DeFi analytics different from traditional SaaS analytics?
In traditional SaaS, the entire user journey happens inside your application, and tools like Google Analytics or Mixpanel can see everything. In DeFi, the user journey is split across two data planes: offchain (browsing, clicking links, connecting a wallet) and onchain (swaps, deposits, mints). These halves use different identifiers, live in different databases, and follow different privacy models. Bridging them is the core challenge, and it's why standard Web2 analytics tools only capture half the picture.
Can I use Google Analytics or Mixpanel for my DeFi protocol?
You can, but they'll only track what happens in the browser. GA4 has no concept of a wallet, so when a user connects their wallet and executes a swap, GA4 sees a button click at best. Mixpanel and Amplitude require custom instrumentation to map their identity systems to wallet addresses. These tools solve the offchain half of the problem well, but connecting marketing spend to actual onchain conversions requires either significant custom engineering or a crypto-native analytics platform.
How does wallet-based identity resolution work?
Crypto-native tools use the wallet address as the primary identity. When a user connects their wallet, the platform links that address to the offchain session data it has already collected (referrer, UTM parameters, page views). This means the same user on two different devices or browsers is recognized as one person as long as they connect the same wallet. The limitation is that users with multiple wallets appear as separate users, and multisig or smart contract wallets may not be attributed correctly depending on how the interaction is routed.
What is ERC-8021 and why does it matter for attribution?
ERC-8021 is a standardized attribution protocol for EVM-compatible blockchains. It allows applications to claim credit for transactions they facilitate by appending attribution data to transaction calldata. A parser reads from the end of the calldata and checks for the 0x8021 marker in the final 16 bytes to extract attribution information. The gas overhead is minimal (100-400 gas per transaction), no smart contract modifications are needed, and multiple applications can receive attribution in a single transaction. This matters because it provides onchain attribution that works even when users interact through aggregators or direct contract calls rather than your frontend.
What's the difference between onchain data platforms (Dune) and crypto-native analytics tools (Formo, Spindl)?
Onchain data platforms let you query blockchain data with SQL. They're excellent for protocol-level analysis (TVL, volumes, wallet behavior) and competitive research, but they don't track offchain behavior at all. Not all that matters happens onchain. They can tell you what happened onchain, not why it happened or which channel or marketing campaign drove it. Crypto-native analytics tools bridge the offchain and onchain gap, connecting marketing efforts and product interactions to actual onchain conversions at the wallet level.
Should I build my own analytics pipeline or buy an off-the-shelf solution?
It depends on what you need and the engineering resources you have. Marketing attribution and identity resolution are the strongest arguments for buying, as building reliable wallet-to-session linking from scratch is a multi-month engineering project with ongoing maintenance. Building makes sense for real-time onchain data that powers your frontend (subgraph indexing), highly specific analytical requirements, or onchain-only research (where Dune excels). Most teams underestimate the maintenance cost, time to value, and data quality challenges of custom builds.
How do DeFi analytics tools handle privacy?
It varies significantly. Web2 tools like GA4 store IP addresses, use device fingerprinting and third-party cookies, and require GDPR consent banners. Crypto-native tools like Formo avoid these practices entirely, using wallet addresses as pseudonymous identities without storing IPs, fingerprinting devices, or using third-party cookies. Onchain data platforms sidestep the question because they only work with data that's already public on the blockchain. The privacy model of your analytics stack matters in crypto because your users chose decentralized protocols in part because they value control over their data.
What analytics stack should an early-stage DeFi protocol use?
For early-stage teams, a crypto-native analytics platform like Formo for unified web, product, and onchain analytics, combined with DefiLlama for protocol benchmarking and Dune for ad hoc onchain queries, covers the essential bases without requiring significant infrastructure and custom engineering. This stack gives you full-funnel visibility from traffic source through onchain conversion in much less time, which is what you need to make informed growth decisions. Adding complexity (session replay, wallet intelligence, custom pipelines) makes more sense once you've validated product-market fit and have specific analytical needs that outgrow the core stack.
Teams looking for answers to common questions around attribution, wallet intelligence, and growth measurement can explore our DeFi analytics FAQs.


